
The Tokenmaxxing Era

A single Meta engineer burned through 281 billion tokens in 30 days — enough text to fill Wikipedia 44 times over. At current API rates, that’s roughly $420,000 in compute. Meta didn’t fire him - but rather gave him a badge called “Token Legend.”
Meanwhile, Nvidia CEO Jensen Huang told the All-In Podcast that he’d be “deeply alarmed” if a $500,000 engineer wasn’t consuming at least $250,000 in AI tokens per year. Shopify CEO Tobi Lütke made “reflexive AI usage” a baseline performance expectation and added AI consumption questions to peer reviews. Meta has also begun integrating AI usage into its performance culture — its internal “Claudeonomics” leaderboard gamifies consumption, and leadership has publicly encouraged engineers to maximise their token spend.
These leaders are responding to something real: most companies are still dramatically underusing AI, and a push toward adoption makes strategic sense. But the way we measure that adoption is about to matter enormously — and I don’t think we’ve figured it out yet.
When usage becomes a scoreboard
The term has already entered the lexicon: tokenmaxxing — the competitive consumption of AI compute as a signal of productivity. Meta’s “Claudeonomics” leaderboard tracks usage across 85,000 employees and ranks the top 250 power users. In a recent 30-day window, employees collectively consumed 60 trillion tokens — roughly $90 million in compute at standard API rates, or $1.08 billion annualised.

The gamification is deliberate. Employees earn badges from bronze to emerald. Titles include “Session Immortal” and “Model Connoisseur.” An OpenAI engineer reportedly consumed 210 billion tokens in a single week — 33 complete Wikipedias. Gizmodo reported that multiple tech companies are now evaluating employees in part by how quickly they burn through LLM tokens.
On April 2, 2026, OpenAI formalised the economics by moving Codex to token-based pricing, replacing per-seat licenses with pay-as-you-go billing. Anthropic’s enterprise plans already operate on per-token economics. The infrastructure now exists to track every interaction, every query, every dollar — down to the individual.
For the first time, knowledge work has a variable cost that’s attributable at the person level. But it means companies need to decide: what are we actually optimising for?
More tokens don’t mean more output — up to a point
Here’s the hypothesis I think matters most, and the one I’d want to test if I were running an AI-forward engineering org. The relationship between token consumption and productivity isn’t linear. It’s an inverted U.
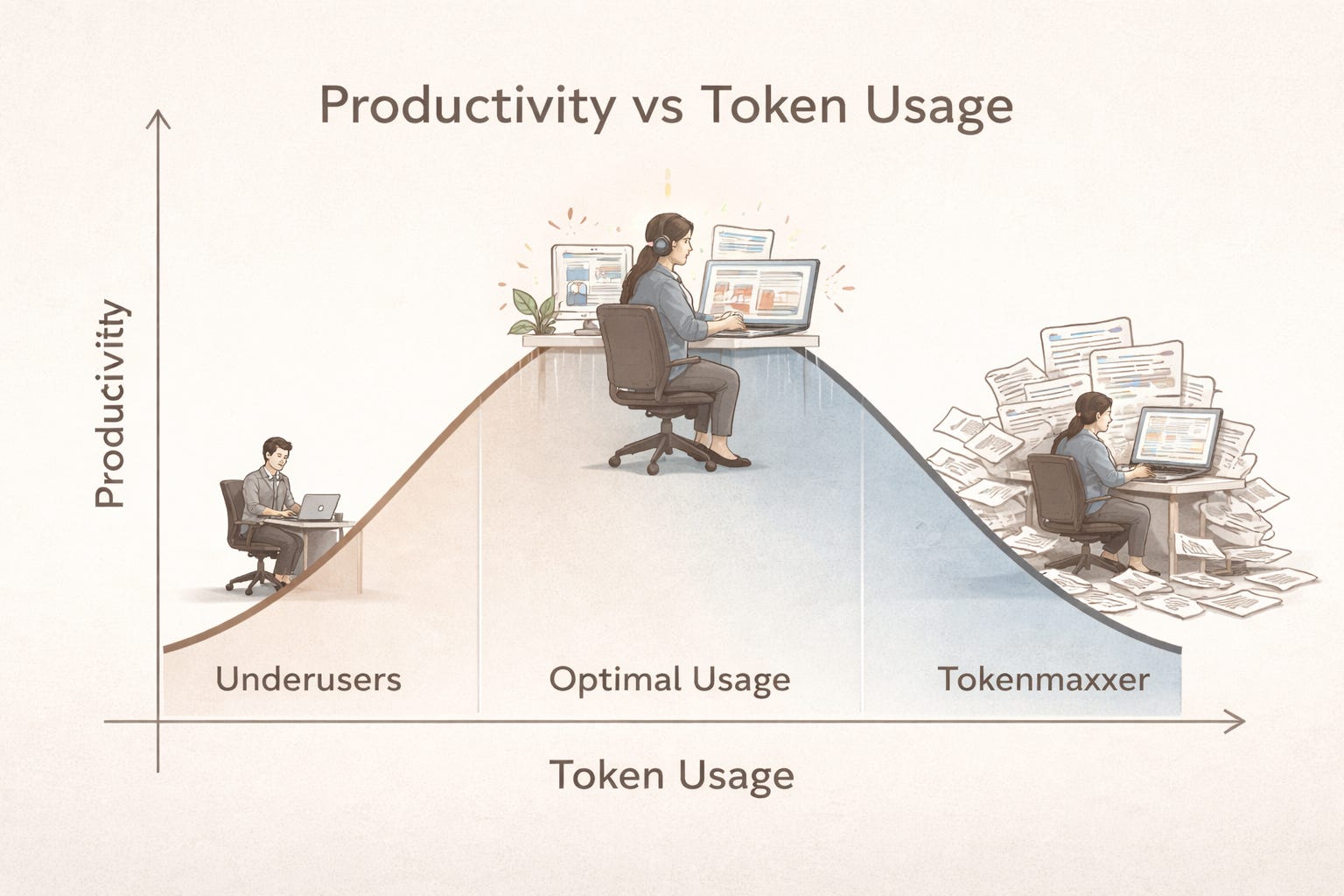
At the left end of the curve, you have zero or minimal usage — people who haven’t adopted AI at all, either from friction, scepticism, or lack of training. They’re leaving real value on the table. Research from MIT Sloan found that the least experienced workers gained up to 35% more output per hour with AI access, while highly skilled consultants given structured AI guidance achieved gains exceeding 40%. The average boost was 14%, but the distribution is what matters: the gap between a skilled AI user and an unskilled one isn’t marginal - it’s a multiple.
In the middle, you have the sweet spot: people who use AI selectively and precisely. They get useful output on the first or second try. They apply AI to problems where it genuinely saves time — drafting, analysis, code generation, research synthesis — and do the rest themselves. Their token consumption is moderate. Their output is disproportionately high.
At the right end, you have the tokenmaxxers — people who use AI as a default for everything, including tasks they’d complete faster on their own. They re-prompt the same request twelve times because they can’t articulate what they want. They generate content nobody asked for. Some keep sessions running just to climb the rankings. Their marginal productivity may actually be negative once you account for the cost of reviewing, correcting, and discarding output that wasn’t needed.
If this curve is real — and I suspect any honest internal analysis would confirm it — then the optimisation problem is more interesting than “encourage more usage” or “control costs.” It’s about finding the peak for each function, and building systems that push people toward it.
Why $15 gets more scrutiny than $5,000
There’s a second-order effect here that I haven’t seen discussed, and it may matter more than the measurement question.
When AI usage becomes a visible, per-person cost line, the cost of using AI becomes salient in a way that the cost of not using AI never does.
A senior analyst spends three days manually synthesising data from multiple sources — a task that a well-constructed AI workflow could accomplish in two hours for perhaps $15 in token costs. The three days of analyst time cost the company roughly $3,000–5,000 in loaded salary. But that cost is invisible - it’s buried in headcount — a fixed line item nobody examines at the task level.
Now imagine the analyst uses AI instead. The $15 shows up on a dashboard. It’s variable and attributable. If the culture is one of cost scrutiny, the analyst learns that AI usage attracts attention in a way that slow manual work never does.
This asymmetry is the real risk. The cost of AI is measured in dollars on a dashboard. The cost of not using AI is measured in invisible hours nobody tracks. Any organisation that manages token spend without simultaneously measuring time-to-completion will systematically underinvest in the high-value applications — which is the opposite of what you want.
What organizations should put on the dashboard"
So how do you manage AI as a cost line without suppressing the behaviour you’re trying to encourage? Here’s what I think would actually work.
Give teams a budget, not individuals a score. Set a monthly compute allocation at the team level and let them self-optimise. Teams will figure out which applications are worth the tokens because they’re closest to the work. Nobody earns a badge, but every team has an incentive to spend wisely.

Track what came out, not just what went in. The number you want isn’t “how many tokens did this team use.” It’s “what changed because they used them.” Deals closed, features shipped, reports delivered, time-to-completion on recurring tasks — track those alongside consumption. A team whose output rises faster than its spend is using AI well, regardless of the absolute number.
Talk to both ends of the spectrum. Zero-usage teams need a conversation about barriers — tooling, training, use-case identification. The research consistently shows the least experienced workers gain the most from AI, so non-adoption is costliest where it’s most common. High-usage teams need a different conversation: what did you build? If a team burned $50,000 in tokens and automated a workflow that saves $500,000 annually, celebrate it. If they burned $50,000 and produced nothing measurable, that’s worth understanding too.
Put the hidden cost on the dashboard too. If you track AI spend per team, also track estimated time savings - force the comparison. A team that spends $10,000 a month but saves 200 analyst-hours is generating a 5–10x return. Without that context, the spend number means nothing.
Treat compute like R&D, not like office supplies. Jensen Huang’s instinct — that engineers should be spending heavily on AI — is right in principle. The companies that extract the most value will treat compute as investment in capability, not consumption to be minimised. The question is whether that investment is directed toward outcomes or toward leaderboard positions.
—
Full disclosure: I’ve drifted off and token-maximised plenty of times myself ;)
Sources:
Very cool insights Noelle!